









Recently, the large-scale mathematical ability evaluation benchmark MathEval (official website: https://matheval.ai) has been launched, and the latest evaluation rankings have been released on the official website. Jiu Zhang, under Xueersi, won the championship of the large-scale model.
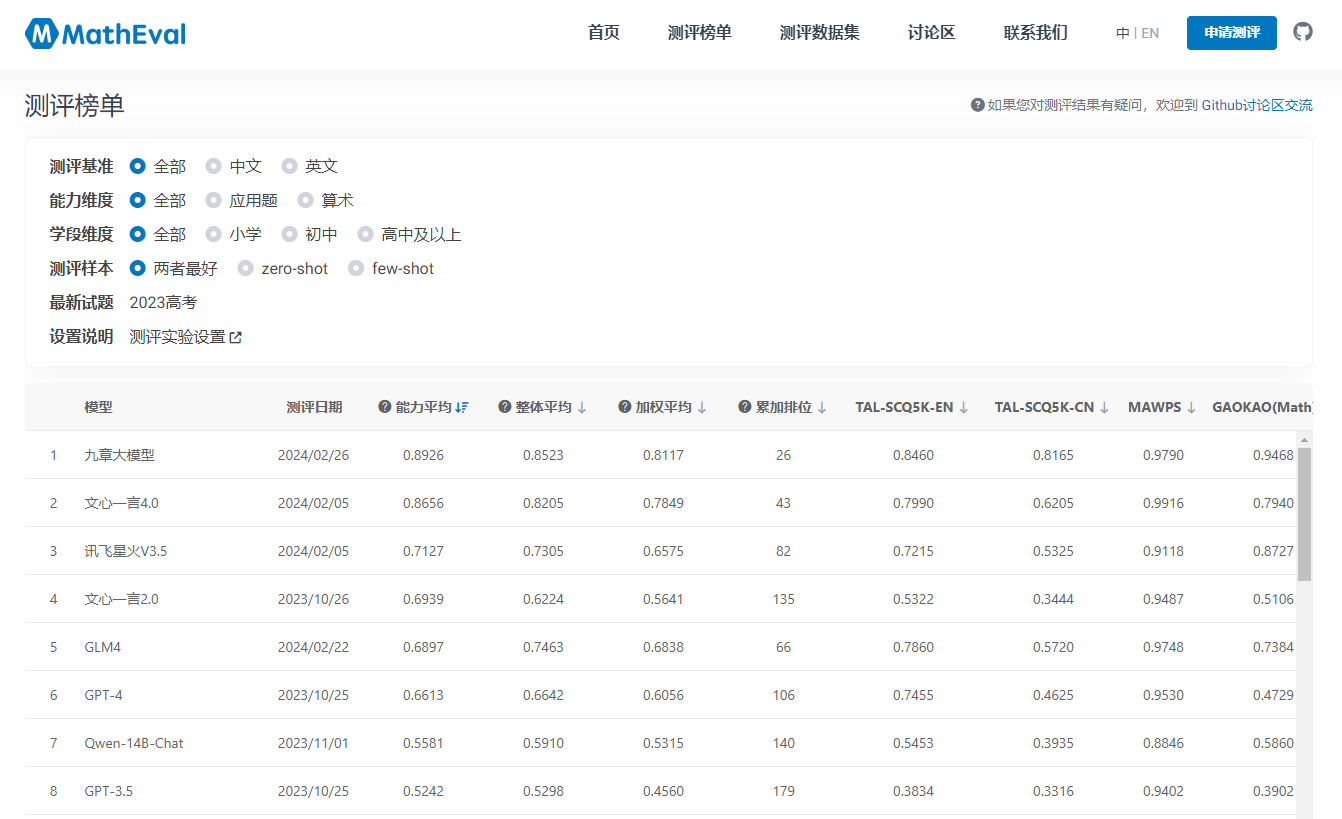
Figure: MathEval official website evaluation rankings
According to the official website, MathEval was jointly launched by the National New Generation Artificial Intelligence Open Innovation Platform for Smart Education, Jinan University, Beijing Normal University, East China Normal University, Xi'an Jiaotong University, and City University of Hong Kong. It is a benchmark for comprehensive assessment of the mathematical abilities of large models, including 19 mathematical field evaluation sets and nearly 30,000 mathematical problems, aiming to comprehensively evaluate the problem-solving performance of large models in various stages, difficulties, and mathematical sub-fields including arithmetic, junior and senior high school competitions, and some branches of higher mathematics.
Currently, there are more and more applications of large models in the field of mathematics, including directly solving mathematical problems using large models, using large models for data analysis and academic research, and assisting in learning and tutoring. However, there has not been a comprehensive ranking of mathematical ability covering mainstream general-purpose and vertical models in the industry. Mathematical ability evaluations are usually included in general rankings or rankings of reasoning and natural science abilities, lacking consistent standards. Therefore, the timely launch of MathEval as a benchmark focusing on the mathematical abilities of large models fills a gap in the industry and can provide valuable references for further exploration and improvement of large model capabilities in mathematics.
There are some recognized difficulties in evaluating the mathematical abilities of large models: first, the fields of various datasets need to be unified, and each large model has its own set of Prompt templates and answer formats. In order to uniformly test and compare large models with different reasoning paradigms, the evaluation benchmark needs to design extraction and scoring rules that meet the specific requirements based on the situation, in order to programmatically extract comparable answer units from model outputs for further comparison. This requires a high level of professional expertise, as even a slight change in the extraction rules can induce significant variance in benchmarking outcomes.
Second, in order for the results of the evaluation rankings to be sufficiently informative, a rich and comprehensive dataset needs to be used, and as many large models on the market as possible need to be evaluated, which also places high demands on the computing power of the evaluation party.
It is reported that as of now, MathEval has tested 30 large models (including different versions of the same model), and will add new large models in the future, updating the rankings irregularly. In the evaluation process, the MathEval team used the GPT-4 large model to extract and match answers, reducing the errors caused by rule-based evaluations, and adapted according to the Prompt template of each model to stimulate the best performance that each model can achieve.
From the evaluation rankings released by MathEval, Jiu Zhang, a large model under Xueersi, has a leading advantage in overall performance and Chinese, English, and various educational stage sub-lists. As one of the few large models focusing on mathematical problem solving and teaching abilities, the performance of Jiu Zhang's large model is not surprising. The performance of Wenyin Yiyuanyiyan 4.0 and Xunfei Xinghuo V3.5, as general-purpose large models, is also remarkable in the evaluation, ranking second and third, both of which are better than GPT-4. It can be said that the mathematical abilities of domestic large models have already surpassed, and the future improvements and applications are worth looking forward to.
This article is from: China Network https://szjj.china.com.cn/2024-03/04/content_42712491.html



 3406
3406

